
Fostering Jagged People – For Science!

By: Carolyn Olsen
Data science is made for jagged people.
In his book The End of Average, Harvard University’s Todd Rose talks about how no one is average. Average is a statistical myth. We all have strengths and weaknesses, and evaluating talent based on a single number like a GPA or an SAT doesn’t work. In Rose’s terms, people are jagged.
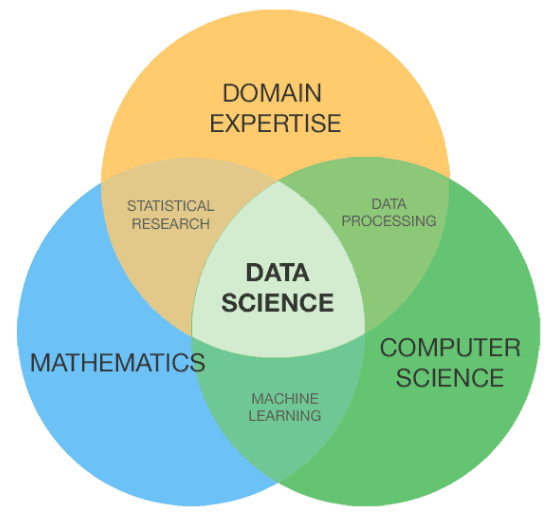
Data science is the science and art of extracting meaning from data. It can solve problems ranging from diagnosing potential lung diseases with medical scans, to detecting fraud, to identifying products or services to target to which people (like Netflix or Amazon recommendations). It is interdisciplinary, combining business and domain knowledge with computer science, statistics, math, and communication.
Data science and analytics are needed in all industries and all signs point to them being vital skills needed across more and more professions.
Often students learning statistics or data science are taught how to analyze data, but are given sterilized, clean data sets ready for analysis – when in the real world, getting messy, disjointed data prepped can be 80% of the work. As a hiring manager, if someone has experience getting their own data ready, that means that much less work for me when they come on board, because that person will be more self-sufficient coming out of the gate. Luckily for students and educators alike, opportunities abound these days for hands-on practice with data, with free data sets and data science problems available online several places including Kaggle. Additionally, platforms such as Headrush Learning enable innovative schools to embrace, defend, and showcase more agile, cross-curricular approaches to learning that cultivate that kind of talent.
It’s such an interdisciplinary and evolving field, in fact, that we can’t even get our terminology straight. Practitioners coming from a computer science or programming background talk more about “artificial intelligence” and “machine learning.” Practitioners from a statistics or analytics background are more likely to say “predictive modeling,” “predictive analytics,” or “statistical modeling,” even when the math we’re talking about is exactly the same, and being used for the same purpose. (Technical aside: Machine learning is a subset of artificial intelligence. Data science often uses machine learning methods for things like predictive modeling where we predict a possible outcome based on historical patterns.)
But the more important effect of data science’s interdisciplinary nature is that data science is a team sport.
Yes, there are “full-stack data scientists” who build and deploy machine learning models that perform well. But more often, the people who come together to build data science solutions have areas of expertise. For example, one might be best at the data engineering needed to prepare a dataset for analysis. Another might be a statistical whiz. These people go deep in one or more areas of data science. When they come together, they can produce better, faster results than a single data scientist working alone who does all parts of a project “OK.”
In my own work as a data scientist, I often partner with a colleague who specializes in engineering and architecture. I can train the socks off a machine learning model, and I could struggle my way through the engineering side – but it’s better for everyone, especially the paying client, if a specialist tackles that portion.
Five to ten years ago, when data science was just beginning to emerge as a hot field, there were no “data science” education programs. Data science teams were built with people from a variety of fields. My own training was in applied economics, and I’ve worked with teammates trained in computer science, statistics, and physics. Today, there are more and more data science programs at universities. Those programs aim to capture the interdisciplinary nature of data science, but often will be stronger in one area than another – and you can guess which by seeing which department hosts the program— a computer science department, expects strong engineering training, for example. The diverse nature of data science education is good, because it helps foster the complementary skillsets that make data science teams successful.
The combination of this ‘deeper learning’ with an idea that co-founder of Headrush Learning Shane Krukowski shared with me, of ‘liberating learning’ from the confines of how knowledge has been traditionally organized, feels very relevant and directly correct. In data science, a person with a variety of deep experiences in a few aspects of data science can be more insightful, and produce higher quality work, than someone who skirts along the surface evenly.
My advice to students interested in data science is this:
Choose your own adventure!
Data science requires an exciting, complex hodge-podge of skills. But while you’re choosing your own adventure, be aware of your own strengths and weaknesses. Know your jagged profile. Based on that, find peers and mentors who complement your skills, to take your data science to the next level.
Reflecting on all of this, I’d expand my original headline a bit wider and give the same advice to all students, regardless of potential career field… get more hands-on experience, learn to work well as part of a team, know your jagged profile, and find peers and mentors who complement your skills. That’s what my data tells me, anyway.
For more, see:
- Supporting Statewide Change Through Microgrants to Families
- Ada Palmer on Learning from the Past and the Future
- Rebellion as an Act of Community and Self-Love
Carolyn Olsen is Principal Data Scientist at Octavian Technology Group, where she helps clients identify and execute on opportunities to leverage data for better or more automated decision-making. She has built data science solutions for insurance, finance, healthcare, and marketing, for companies ranging from small businesses to Fortune 100. She loves geeking out about data science, so if you’d like to chat, please reach out.
Stay in-the-know with innovations in learning by signing up for the weekly Smart Update.






0 Comments
Leave a Comment
Your email address will not be published. All fields are required.